Upload date
All time
Last hour
Today
This week
This month
This year
Type
All
Video
Channel
Playlist
Movie
Duration
Short (< 4 minutes)
Medium (4-20 minutes)
Long (> 20 minutes)
Sort by
Relevance
Rating
View count
Features
HD
Subtitles/CC
Creative Commons
3D
Live
4K
360°
VR180
HDR
43 results
CMU Database Group - Quarantine Tech Talks (2020) Speaker: Cheng Lian + Maryann Xue (DataBricks) A Deep Dive into Spark ...
6,083 views
5 years ago
In last video I have discussed about the program where you can develop big data project, and see big data use cases that include ...
1,323 views
This video provides a practical guide to using Apache Spark, focusing on running Spark locally with Docker and Databricks ...
214 views
1 year ago
Maggy: Asynchronous distributed hyperparameter optimization based on Apache Spark Asynchronous algorithms on a ...
630 views
Prof. Andy Pavlo (https://www.cs.cmu.edu/~pavlo/) Slides: https://15721.courses.cs.cmu.edu/spring2023/slides/20-databricks.pdf ...
15,149 views
2 years ago
In this video I have explained 10 Big data issues, that I have faced in Big data project, while working on them. To become a ...
19,686 views
Gain a unique perspective on the technical and problem-solving skills expected of senior data engineers in this very little edited ...
19,299 views
Apache Spark Performance Tuning | Resource Allocation with 4 Node Cluster | Hands on Example Discussion Forum ...
1,409 views
4 years ago
by Holden Karau At: FOSDEM 2019 https://video.fosdem.org/2019/UA2.118/validating_big_data_jobs.webm If you, like close to ...
497 views
6 years ago
Data Engineers face many challenges with Data Lakes. GDPR requests, data quality issues, handling large metadata, merges ...
183 views
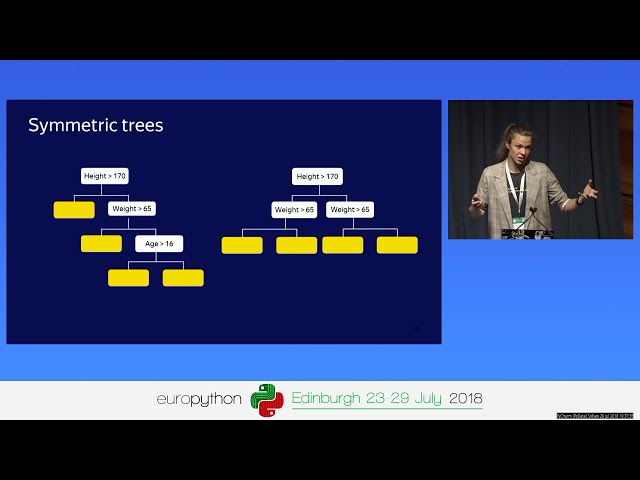
CatBoost - the new generation of Gradient Boosting [EuroPython 2018 - Talk - 2018-07-26 - PyCharm [PyData]] [Edinburgh, UK] ...
14,452 views
7 years ago
Thank you to all of of our ApacheCon@Home 2021 sponsors, including: STRATEGIC --------------- Google PLATINUM ...
3,293 views
In spite of huge progress in Artificial Intelligence and Machine Learning over the past decade, building production ready ...
664 views
Data in the 21st Century is like Oil in the 18th Century: an immensely, untapped valuable asset if processed in an intelligent way.
252 views
Hyperparameter Tuning Using Kubeflow - Richard Liu, Google & Johnu George, Cisco Systems In machine learning, ...
591 views
Accelerating distributed joins in Apache Hive: Runtime filtering enhancements Panagiotis Garefalakis, Stamatis Zampetakis A ...
245 views
Speaker: Michael McCune Although there are several popular frameworks that have arisen in the past few years to address the ...
162 views
Do you have plans to start working with Apache Spark? Are you already working with Spark but you haven't gotten the expected ...
760 views
8 years ago
CMU Database Group - Vaccination Database Tech Talks - Second Dose (2021) Speakers: Steven Phillips + Vivekanand Vellanki ...
3,181 views
... the feature extraction process to a clustered ts fresh handles larger than memory data utilizing task and pi spark however i am ...
1,892 views