Upload date
All time
Last hour
Today
This week
This month
This year
Type
All
Video
Channel
Playlist
Movie
Duration
Short (< 4 minutes)
Medium (4-20 minutes)
Long (> 20 minutes)
Sort by
Relevance
Rating
View count
Features
HD
Subtitles/CC
Creative Commons
3D
Live
4K
360°
VR180
HDR
15 results
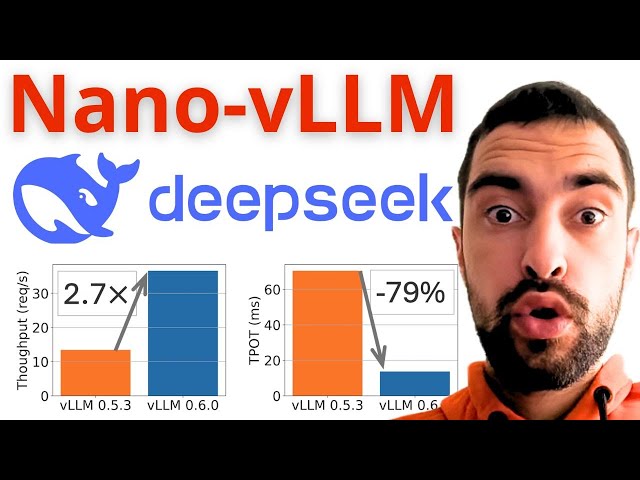
repo - https://github.com/GeeeekExplorer/nano-vllm/tree/main * Nano-vLLM is a simple, fast LLM server in \~1200 lines of Python ...
1,682 views
9mo ago
Speaker(s): Rehan Samaratunga My auto-tuning project aims to find the best settings for running large language models using ...
117 views
5mo ago