Upload date
All time
Last hour
Today
This week
This month
This year
Type
All
Video
Channel
Playlist
Movie
Duration
Short (< 4 minutes)
Medium (4-20 minutes)
Long (> 20 minutes)
Sort by
Relevance
Rating
View count
Features
HD
Subtitles/CC
Creative Commons
3D
Live
4K
360°
VR180
HDR
967 results
Explore VLLM deployment on Linux! We explain installation via pip, showcasing visual details & inferencing. Got questions about ...
2,654 views
9 months ago
Explore VLLM's groundbreaking performance! We highlight up to 24x throughput improvements over Hugging Face Transformers ...
1,290 views
Best Deals on Amazon: https://amzn.to/3JPwht2 MY TOP PICKS + INSIDER DISCOUNTS: https://beacons.ai/savagereviews I ...
24,518 views
6 months ago
Ever wonder what the 'v' in vLLM stands for? Chris Wright and Nick Hill explain how "virtual" memory and paged attention ...
7,950 views
8 months ago
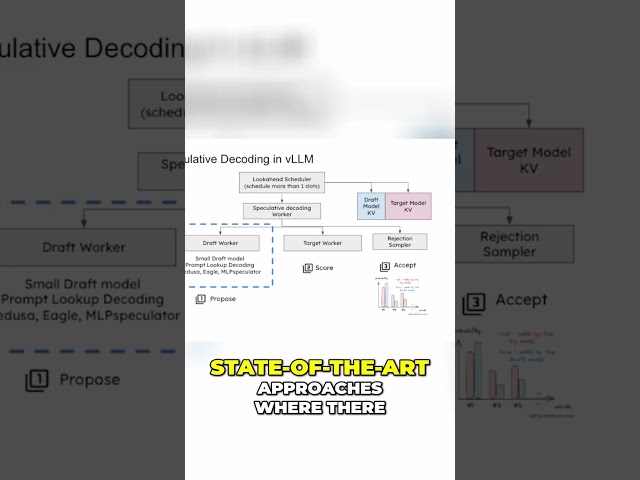
Explore VLLM's speculative decoding and its evolution within the open-source community. We delve into cutting-edge ...
708 views
10 months ago
Step by step guide: https://github.com/Quick-AI-tutorials/AI-Infra/tree/main/2025-09-22%20LMCache%20Dynamo LMCache: ...
2,728 views
Best Deals on Amazon: https://amzn.to/3JPwht2 MY TOP PICKS + INSIDER DISCOUNTS: https://beacons.ai/savagereviews I ...
2,097 views
3,728 views
Explore Paged Attention's functionality in memory management! We explain how it divides memory into pages, accesses only ...
1,341 views
Running AI models locally in 2026? Your top three options are Ollama, vLLM, and Llama.cpp—but they're built for completely ...
1,317 views
4 months ago
The High-Throughput and Memory-Efficient inference and serving engine for LLMs Easy, fast, and cost-efficient LLM serving for ...
40 views
3 weeks ago
In our latest episode we sat down with Rob Shaw. We explored both vLLM and llm-d highlighting the innovative approach to ...
1,658 views
7 months ago
Unlock the full potential of your AI models by serving them at scale with vLLM. This video addresses common challenges like ...
1,380 views
The AI revolution demands a new kind of infrastructure — and the AI Lab video series is your technical deep dive, discussing key ...
8,201,608 views
vLLM vs. Other LLM Inference Frameworks The strengths and weaknesses of various large language model (LLM) inference ...
105 views
1 year ago
Serving modern AI models has become quite complicated different stacks for LLMs, vision models, audio, and video inference.
1,115 views
3 months ago
Get started with just $10 at https://www.runpod.io vLLM is a high-performance, open-source inference engine designed for fast ...
2,156 views
5 months ago
RESOURCES & DOCUMENTATION • Full Documentation: https://docs.olares.com/manual/overview.html • Download LarePass: ...
946 views
12,431 views
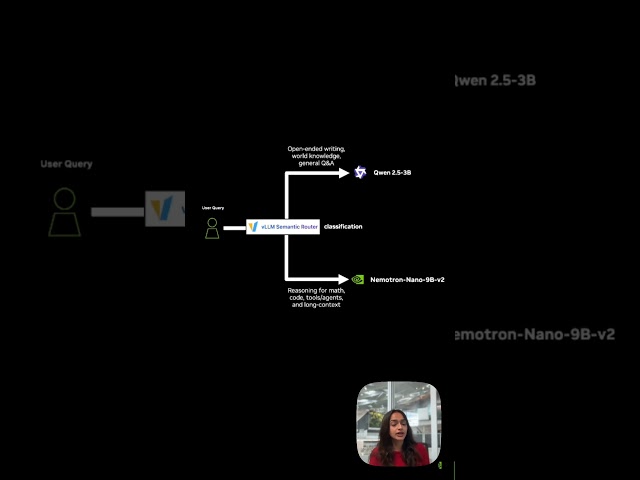
nvidia #machinelearning #vllm #ai.
7,216 views
2 months ago









![vLLM Explained in 2 Min [2026] | 2 Min Series of Tech |](/api/proxy/image?url=https%3A%2F%2Fi.ytimg.com%2Fvi%2FZiiL_loyOes%2Fsddefault.jpg)