Upload date
All time
Last hour
Today
This week
This month
This year
Type
All
Video
Channel
Playlist
Movie
Duration
Short (< 4 minutes)
Medium (4-20 minutes)
Long (> 20 minutes)
Sort by
Relevance
Rating
View count
Features
HD
Subtitles/CC
Creative Commons
3D
Live
4K
360°
VR180
HDR
4,485 results
Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ...
71,403 views
10 months ago
Today we learn about vLLM, a Python library that allows for easy and fast deployment and inference of LLMs.
36,360 views
6 months ago
vLLM: Easy, Fast, and Cheap LLM Serving for Everyone - Simon Mo, vLLM vLLM is an open source library for fast, easy-to-use ...
3,444 views
4 months ago
Ready to serve your large language models faster, more efficiently, and at a lower cost? Discover how vLLM, a high-throughput ...
12,938 views
8 months ago
Best Deals on Amazon: https://amzn.to/3JPwht2 MY TOP PICKS + INSIDER DISCOUNTS: https://beacons.ai/savagereviews I ...
23,917 views
Learn how to run an open-source LLM locally using VLLM and Docker with GPU support. In this 2026 guide, you'll set up a VLLM ...
1,613 views
2 months ago
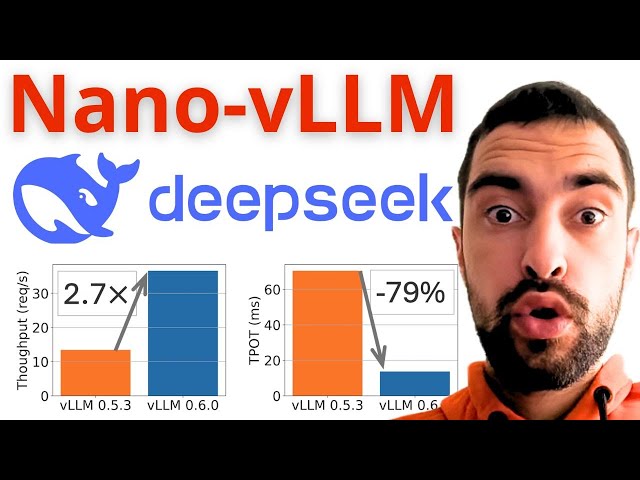
repo - https://github.com/GeeeekExplorer/nano-vllm/tree/main * Nano-vLLM is a simple, fast LLM server in \~1200 lines of Python ...
1,681 views
9 months ago
Discover which LLM inference engine truly delivers the best performance! In this comprehensive benchmark, I put vLLM and ...
1,455 views
1 month ago
This video covers 15 trending AI projects on GitHub right now, including MoneyPrinterV2, trivy, Agent-S, protobuf, and vllm-omni.
293 views
6 days ago
Running AI models locally in 2026? Your top three options are Ollama, vLLM, and Llama.cpp—but they're built for completely ...
1,253 views
consulting: https://openclaw.productdeploy.com/ NVIDIA NemoClaw is an open source stack that adds privacy and security ...
860 views
Learn how to easily install vLLM and locally serve powerful AI models on your own GPU! Buy Me a Coffee to support the ...
16,888 views
11 months ago
Download SwifDoo PDF: ...
5,676 views
4 days ago
I walk through how a transformer-based Large Language Model (LLM) generates text. From tokenization to embeddings, ...
4,114 views
Most AI models today are stuck in a world of words, but the future is omnimodal. In this video, we break down vLLM-Omni, a new ...
228 views
3 months ago
Explore VLLM deployment on Linux! We explain installation via pip, showcasing visual details & inferencing. Got questions about ...
2,617 views
Running large language models locally sounds simple, until you realize your GPU is busy but barely efficient. Every request feels ...
2,421 views
Explore VLLM's groundbreaking performance! We highlight up to 24x throughput improvements over Hugging Face Transformers ...
1,288 views
In this video, we understand how VLLM works. We look at a prompt and understand what exactly happens to the prompt as it ...
15,551 views
Ever wonder what the 'v' in vLLM stands for? Chris Wright and Nick Hill explain how "virtual" memory and paged attention ...
7,827 views
This tutorial is a step-by-step hands-on guide to locally install vLLM-Omni. Buy Me a Coffee to support the channel: ...
6,472 views
Welcome to our introduction to VLLM! In this video, we'll explore what VLLM is, its key features, and how it can help streamline ...
8,642 views
1 year ago
In this video, you'll get your GPU-enabled machine running vLLM, a leading open-source library for efficiently serving LLMs and ...
301 views
Best Deals on Amazon: https://amzn.to/3JPwht2 MY TOP PICKS + INSIDER DISCOUNTS: https://beacons.ai/savagereviews I ...
2,091 views
vllm #llm #machinelearning #ai #llamasgemelas It takes a significant amount of time and energy to create these free video ...
3,697 views
At Ray Summit 2025, Tun Jian Tan from Embedded LLM shares an inside look at what gives vLLM its industry-leading speed, ...
1,658 views
LLMs promise to fundamentally change how we use AI across all industries. However, actually serving these models is ...
61,286 views
2 years ago
In this video, we build a fully self-hosted coding agent powered by the 7B parameter Qwen 2.5 Coder model, running on a GPU ...
1,360 views
2 weeks ago
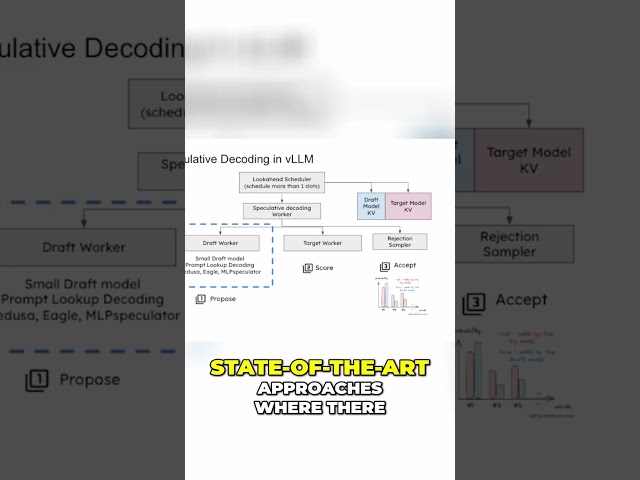
Explore VLLM's speculative decoding and its evolution within the open-source community. We delve into cutting-edge ...
702 views