Upload date
All time
Last hour
Today
This week
This month
This year
Type
All
Video
Channel
Playlist
Movie
Duration
Short (< 4 minutes)
Medium (4-20 minutes)
Long (> 20 minutes)
Sort by
Relevance
Rating
View count
Features
HD
Subtitles/CC
Creative Commons
3D
Live
4K
360°
VR180
HDR
4,773 results
Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ...
74,048 views
10 months ago
Today we learn about vLLM, a Python library that allows for easy and fast deployment and inference of LLMs.
38,846 views
7 months ago
vLLMs Labs for FREE — https://kode.wiki/4toLSl7 Most people can use an LLM. Very few know how to serve one at scale.
10,216 views
10 days ago
Best Deals on Amazon: https://amzn.to/3JPwht2 MY TOP PICKS + INSIDER DISCOUNTS: https://beacons.ai/savagereviews I ...
27,362 views
vLLM: Easy, Fast, and Cheap LLM Serving for Everyone - Simon Mo, vLLM vLLM is an open source library for fast, easy-to-use ...
3,900 views
5 months ago
Ready to serve your large language models faster, more efficiently, and at a lower cost? Discover how vLLM, a high-throughput ...
13,666 views
8 months ago
Setting up vLLM in our Proxmox 9 LXC host is actually a breeze in this video which follows on the prior 2 guides to give us a very ...
13,040 views
Run Claude Code completely free on Windows using LM Studio — no cloud, no API costs. Real testing, real logs, real ...
6,940 views
2 weeks ago
Here's the one change that took mine from ~120 tok/s to 1200+ without a new GPU. TryHackMe just launched Cyber Security 101 ...
132,957 views
2 months ago
This video teaches how to use and Install PaperClip with Hermes Agent, Gemma 4 and Ollama PaperClip: Open-source ...
11,217 views
4 days ago
Let's test Gemma 4 as a driver (tool calling) for Karpathy's LLM Wiki, in habit/goal tracker Karpathy's LLM Wiki: ...
1,517 views
Streamed 1 day ago
Inferact CEO and co-founder Simon Mo joins Lightspeed partners Bucky Moore and James Alcorn to break down why inference ...
1,024,856 views
Get the Book "Evals for AI Engineers" here: https://learning.oreilly.com/library/view/evals-for-ai/9798341660717/ Coding agents ...
4,127 views
3 weeks ago
I put a tiny MacBook Air between me and some ridiculously large local AI models... and it worked. Power Your Spring Essentials ...
105,666 views
9 days ago
This video demonstrated how to install and use Pi Agent with Ollama and Gemma 4 including skills, extensions and subagents Pi ...
3,107 views
1 day ago
Hermes Agent is a great harness for Local Ai models. I take you through the setup, running with vLLM and integration with ...
23,961 views
8 days ago
Your LLM wiki doesn't have to be just text — here are 10 ways to make it visual, interactive, and actually useful. Try it out yourself!
2,165 views
8 hours ago
vLLM isn't just another inference engine, it's the one that finally solved GPU memory waste at scale The problem: every time ...
15,502 views
2 days ago
Explore VLLM's groundbreaking performance! We highlight up to 24x throughput improvements over Hugging Face Transformers ...
1,312 views
Explore VLLM deployment on Linux! We explain installation via pip, showcasing visual details & inferencing. Got questions about ...
2,823 views
In this video, you'll get your GPU-enabled machine running vLLM, a leading open-source library for efficiently serving LLMs and ...
444 views
1 month ago
Ever wonder what the 'v' in vLLM stands for? Chris Wright and Nick Hill explain how "virtual" memory and paged attention ...
8,334 views
9 months ago
Running large language models locally sounds simple, until you realize your GPU is busy but barely efficient. Every request feels ...
2,737 views
4 months ago
Welcome to our introduction to VLLM! In this video, we'll explore what VLLM is, its key features, and how it can help streamline ...
8,756 views
1 year ago
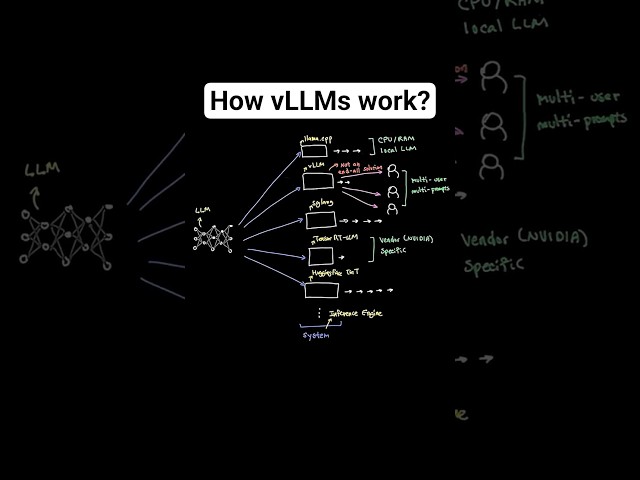
In this video, we understand how VLLM works. We look at a prompt and understand what exactly happens to the prompt as it ...
16,841 views
6 months ago
This tutorial is a step-by-step hands-on guide to locally install vLLM-Omni. Buy Me a Coffee to support the channel: ...
7,067 views
3 months ago
In this video, we build a fully self-hosted coding agent powered by the 7B parameter Qwen 2.5 Coder model, running on a GPU ...
1,896 views
Best Deals on Amazon: https://amzn.to/3JPwht2 MY TOP PICKS + INSIDER DISCOUNTS: https://beacons.ai/savagereviews I ...
2,143 views