Upload date
All time
Last hour
Today
This week
This month
This year
Type
All
Video
Channel
Playlist
Movie
Duration
Short (< 4 minutes)
Medium (4-20 minutes)
Long (> 20 minutes)
Sort by
Relevance
Rating
View count
Features
HD
Subtitles/CC
Creative Commons
3D
Live
4K
360°
VR180
HDR
48 results
vLLMs Labs for FREE — https://kode.wiki/4toLSl7 Most people can use an LLM. Very few know how to serve one at scale.
1,650 views
23 hours ago
Want to make OpenClaw 10x faster on Windows or Linux? In this video, I show you how to replace slow Ollama-style local ...
1,228 views
2 days ago
What's covered: 1. Architecture and design of running inference workloads on k8s. 2. The tools and platforms you need to make it ...
95 views
Install vllm on RTX 5060 Ti 16GB and /5070/5080/5090 GPU Install vLLM on RTX 5060 Ti (16GB) & RTX 5070 / 5080 / 5090 ...
232 views
6 days ago
In this video, we walk through how to self-host the Sarvam-30B model using vLLM, one of the fastest and most efficient inference ...
27 views
5 days ago
Paged Attention is one of the key innovations behind fast LLM inference systems like vLLM. Instead of storing the KV cache as ...
2 views
3 views
🧠 Self-hosting a powerful LLM for OpenClaw – Proactive, private, and API-independent! In this video, Mì AI will guide you ...
2,994 views
10 hours ago
Fix vLLM GPU crashes & Out of Memory (OOM) errors! Process ANY length video locally with Qwen 3.5 Vision. Overcome VLM ...
29 views
1 day ago
Qwen 3.5 Vision was taking 20–30 seconds per video. I got it to 2 seconds. Here's exactly how. This is a complete engineering ...
39 views
Want to upgrade your AI models without downtime? In this video, we explain how to safely swap LLM versions (like Llama 3 ...
Adaptive Inference Router — Overview & Load Test Demo In this video, I walk through the architecture of my Adaptive Inference ...
40 views
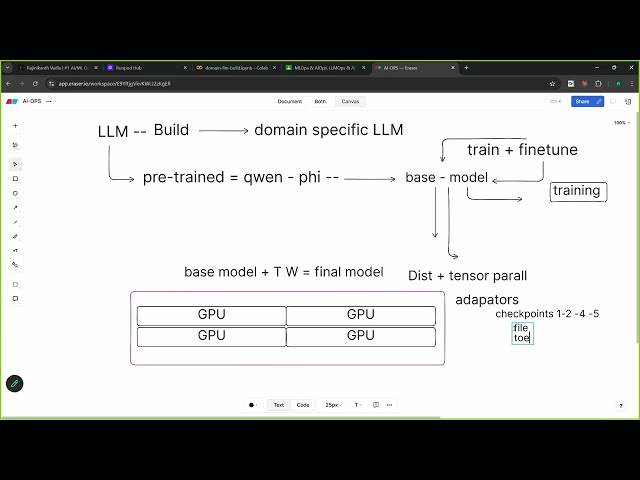
Build a Domain-Specific LLM for Kubernetes Troubleshooting — Real-World AIOps Project In this hands-on tutorial, I'll show you ...
523 views
4 days ago
In this clip from Bill Kennedy's Ultimate AI Workshop, you'll get a practical introduction to the Kronk AI project and the mental ...
363 views
LLM Architecture Gallery: https://sebastianraschka.com/llm-architecture-gallery/ In this video, I take you on a visual tour of modern ...
7,485 views
Read the full article: https://binaryverseai.com/turboquant-kv-cache-compression-engineers-guide/ TurboQuant is one of the most ...
176 views
3 days ago
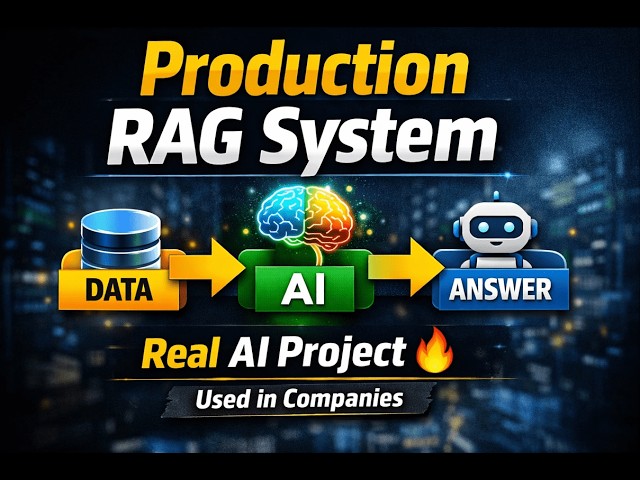
In this video, you will learn how to build a Production-Grade RAG (Retrieval-Augmented Generation) System from scratch used in ...
285 views
7 days ago
Nous Research released Hermes Agent, an open-source agent that doesn't just answer questions; it remembers what it learns ...
11,609 views
Project Gepetto — EP4 NVIDIA DGX Spark: What I Had to Learn Before My LLMs Became Useful --- I picked models that worked.
16 hours ago