Upload date
All time
Last hour
Today
This week
This month
This year
Type
All
Video
Channel
Playlist
Movie
Duration
Short (< 4 minutes)
Medium (4-20 minutes)
Long (> 20 minutes)
Sort by
Relevance
Rating
View count
Features
HD
Subtitles/CC
Creative Commons
3D
Live
4K
360°
VR180
HDR
16 results
Hey everyone, In this video, I showcase how LLM inference has become the primary compute bottleneck in production AI systems.
362 views
1 month ago
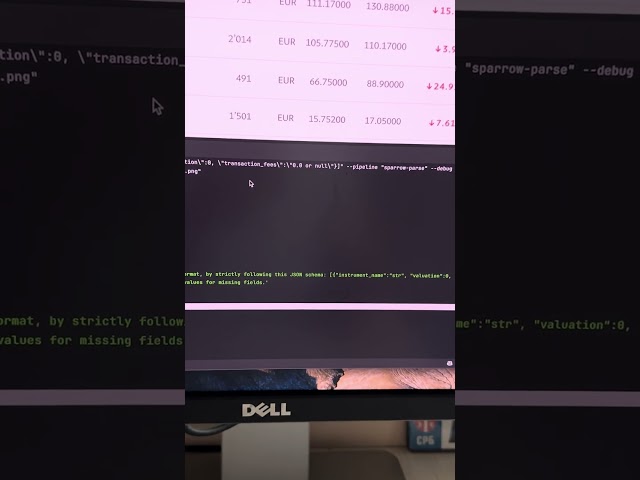
Sparrow structured data extraction supports now non-existing fields. See the example for transaction fees field. If field is not found, ...
171 views
1 year ago
Offloading MLX inference to a subprocess in Sparrow to reclaim memory after API request completes. This is useful when ...
709 views
Running Qwen2 72b 4bit Vision LLM on Mac Mini M4, 64gb makes difference, when running Mini set for High Power mode ...
17,425 views
Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ...
8,935 views
GEMMA 3N + MLX-VLM: Run DeepMind's Revolutionary Multimodal Model on Your Mac! DeepMind just dropped Gemma 3n ...
1,475 views
9 months ago
I built a DIY AI server to see how far a home setup can go without a DGX or a pricey custom workstation. This video covers the ...
24,189 views
7 months ago
I bought this motherboard because it was only $150, and it turned into a home lab for Proxmox, GPU passthrough, and local AI ...
4,038 views
11 days ago
0 views
4 years ago
Xây dựng trợ lý AI tại nhà, chạy bằng điện. Model sử dụng Qwen3-coder-next-awq-4bit. Framework vLLM + openclaw.
393 views
Spec: - 2x5090 (total 64gb vram) - ram 128gb - model: Qwen3-coder-next-awq-4bit (48gb) - framework: vLLM - context 32k - os ...
16 views
ഈ മൂന്ന് രീതികളിൽ വാഷറുകൾ ലൂസാകുന്ന പ്രശനങ്ങൾ പരിഹരിയ്ക്കാം| ...
133,366 views